Creating an Agentic Framework for CAD Model Generation with FreeCAD and PPO Fine-Tuning
What I want to share today is focused dissection of implementing reinforcement learning from human feedback with special emphasis on connecting equations describing proximal policy optimization through the lines of pytorch code that applies PPO to work with CAD model generation. In my approach I let the model generate designs on its own and learn from the score assigned to the design after it is generated.
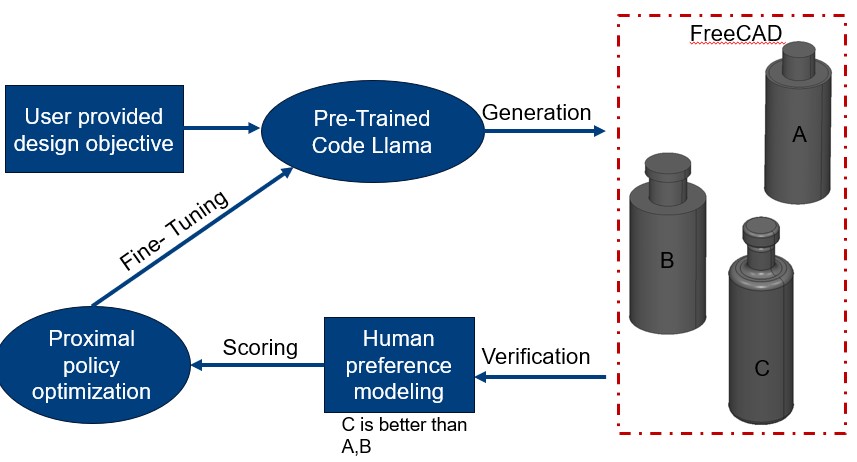
Large language models (LLMs) have shown impressive capabilities in generating and improving content across various domains. Recently, researchers and practitioners have begun exploring how LLMs can assist us in the field of Computer-Aided Design (CAD). This blog post will describe how to build an agentic framework that leverages a language model to generate initial CAD models using FreeCAD, and then fine-tune the process using a Proximal Policy Optimization (PPO) Reinforcement Learning (RL) framework.
By the end of this post, you’ll understand the key components necessary to make LLMs interact effectively with CAD software and how to improve initial designs by optimizing CAD models with reinforcement learning.
Introduction
CAD tools are essential in engineering design, allowing professionals to create 3D models of parts, assemblies, and systems. However, designing CAD models can be a time-consuming task that requires significant expertise. The recent advancements in artificial intelligence, especially in Reasoning ability of LLMs, open up new possibilities to automate the creation and refinement of CAD models.
In this framework, we’ll use FreeCAD [3], an open-source parametric 3D CAD software, as the base tool for design generation. FreeCAD is a versatile 3D CAD modeling tool that uses Python for scripting. By generating Python scripts, we can automate the process of building parametric models in FreeCAD. In our framework, the LLM is tasked with generating these Python scripts based on natural language inputs. We’ll also use a PPO-based reinforcement learning framework to fine-tune the initial models produced by the LLM, making them more precise or aesthetically appealing based on feedback mechanisms.
Framework Overview
Generator
The framework consists of a agentic framework crew ai but one can use any agentic framework to create multi agent communication and execution. We need a generator that will take initial input from a user and provide a plan of action to generate a CAD model.
Generate a Python script for FreeCAD that creates a simple table design.
The output would be a validated .stl file containing the CAD model.
A secondary generator agent receives prompts describing a CAD model and generates scripts in Python compatible with FreeCAD to produce an initial model. FreeCAD interprets the generated Python scripts and creates the 3D model.
import FreeCAD, Part, Mesh
def create_leg(x, y, z, width, height, depth):
"""Creates a single table leg."""
leg = Part.makeBox(width, depth, height)
leg.translate(FreeCAD.Vector(x, y, z))
return leg
def create_tabletop(x, y, z, width, depth, thickness):
"""Creates the tabletop."""
top = Part.makeBox(width, depth, thickness)
top.translate(FreeCAD.Vector(x, y, z))
return top
""" FreeCAD first requires you to create
predefined objectts by calling newDocument"""
if FreeCAD.ActiveDocument is None:
doc = FreeCAD.newDocument()
else:
doc = FreeCAD.ActiveDocument
table_height = 750
leg_height = 700
leg_width = 50
table_width = 1200
table_depth = 800
top_thickness = 50
# Create table legs
legs = []
for i in range(4):
x = (i % 2) * (table_width - leg_width)
y = (i // 2) * (table_depth - leg_width)
leg = create_leg(x, y, 0, leg_width, leg_height, leg_width)
legs.append(leg)
# Create tabletop
tabletop = create_tabletop(0, 0, leg_height, table_width, table_depth, top_thickness)
# Combine all parts into a single object
table = legs[0]
for leg in legs[1:]:
table = table.fuse(leg)
table = table.fuse(tabletop)
# Add table to document
table_object = doc.addObject("Part::Feature", "Table")
table_object.Shape = table
# Recompute the document
doc.recompute()
# Export as STL
stl_file = "/path/to/your/output/table.stl"
Mesh.export([table_object], stl_file)
print("STL file has been created:", stl_file)
 Wooohoo here is our simple but surely a table looking object.
Keep inmind the generator as of this writing can only generate objects with specific complexity. The way I define complexity is number of individual shapes required to develop the final desired object. In my exierience a good part parameter for state-of-the-art LLMs out there like OpenAIo1 is 6-8. Anything above that leads to issues in a good generation, I believe this is due to inherent large context length the model has to track from previous part design responses (Phoebe et al)[1] problem where retrieving information for a large context like this the models looses tracks of the initital objective and begins helucinating.
Wooohoo here is our simple but surely a table looking object.
Keep inmind the generator as of this writing can only generate objects with specific complexity. The way I define complexity is number of individual shapes required to develop the final desired object. In my exierience a good part parameter for state-of-the-art LLMs out there like OpenAIo1 is 6-8. Anything above that leads to issues in a good generation, I believe this is due to inherent large context length the model has to track from previous part design responses (Phoebe et al)[1] problem where retrieving information for a large context like this the models looses tracks of the initital objective and begins helucinating.
Reinforcement Learning
In order to train our model we will first have to generate 1000s of CAD model example, which I recommend using a free generator like GPT3.5 or LLAMA 2.0 if you can self host it. In this case as you can see I am using LLAMA; Once you have run a extreme large number of generation your data you can be organize in following fasion to move to next step which is to train a proximal policy model and setup an environment to learn rewards for your updated policy. The advantage and choice of PPO comes from low computational cost of PPO as it allows for first order optimization (John Schulman et al)[2] using a clipping mechanism that stops the new policy to deviate significantly from previously generated design.
/dataset/
/design_001/
design_001.stl
design_001.fcstd
metadata_001.json
/design_002/
design_002.stl
design_002.fcstd
metadata_002.json
...
Next we would have to process this data into something the a neural network can perceive, often time you could think of this as the atomic state of the data, for example if you have LIDAR data then atomic state here would mean single point in point cloud, if you have mesh file then its the descrete voxel or mesh grid.
import trimesh
import numpy as np
def stl_to_voxel(stl_path, grid_size=32):
mesh = trimesh.load_mesh(stl_path)
voxels = mesh.voxelized(pitch=1.0/grid_size).matrix
return voxels
voxel_grid = stl_to_voxel('/path/to/design.stl')
This function loads the .stl file and converts it into a voxel grid of specified size. In this example, grid_size=32 means the 3D space will be divided into a grid with 32x32x32 voxels. Each voxel is either filled (solid) or empty, representing the 3D shape of the object in the .stl file.
Next we will have to define an environment to train our system, in our case we will use Isaac Gym or Lab as of recently, this env will help us get reward for a given output.
import gym
import numpy as np
from gym import spaces
from utils.stl_to_voxel import stl_to_voxel
from models.generator_llm import GeneratorLLM
class STLEnvironment(gym.Env):
"""
Load target .stl file and convert to voxel grid, define the action space and observation space
"""
def __init__(self, target_stl_path):
super(STLEnvironment, self).__init__()
self.generator_llm = GeneratorLLM()
self.target_voxel = stl_to_voxel(target_stl_path)
self.grid_size = self.target_voxel.shape[0]
self.action_space = spaces.Discrete(1000) # Adjust based on LLM actions
self.observation_space = spaces.Box(0, 1, shape=self.target_voxel.shape, dtype=np.int)
def step(self, action):
"""
Compute reward (e.g., Intersection over Union)
"""
prompt = self.action_to_prompt(action)
generated_stl_path = "/project/stl_files/table.stl"
self.generator_llm.generate_stl(prompt, generated_stl_path)
generated_voxel = stl_to_voxel(generated_stl_path)
reward = self.compute_iou(self.target_voxel, generated_voxel)
done = True # Each episode consists of one action and evaluation
return generated_voxel, reward, done, {}
def reset(self):
"""
Reset environment, potentially load a new target .stl file
"""
return self.target_voxel
def action_to_prompt(self, action):
"""
Map actions to user prompts for the LLM
"""
return f"Generate design {action}"
def compute_iou(self, target_voxel, generated_voxel):
"""
Calculate Intersection over Union (IoU) as the reward
"""
intersection = np.logical_and(target_voxel, generated_voxel).sum()
union = np.logical_or(target_voxel, generated_voxel).sum()
return intersection / union if union != 0 else 0
PPO fine-tunes the LLM using PPO, we will treat the generation of the .stl file as an action in a reinforcement learning environment. The quality of the .stl file, which we can assess by converting it to a voxel grid and comparing it to the target shape or design, provides the reward signal.
How to calculating the Reward? Reward is what we optimize for for example I have a loss function for this approach as
loss = log(σ(𝑟_𝑗 - 𝑟_𝑘))
where r_k is reward from a kth design, and r_j is the improved design from your policy update, sigma is normalization parameter.
The key to fine-tuning with PPO is defining an appropriate reward function. For this task, the reward can be created here based on similarity of shape. We comparing the voxel grid of the generated object to the target object’s voxel grid. Techniques like Intersection over Union (IoU) or Dice coefficient can quantify the similarity. Additional domain-specific metrics can assess whether the object meets specific engineering constraints or aesthetic requirements. Using the reward signal, PPO fine-tunes the LLM, adjusting the model’s weights to improve its ability to generate accurate .stl files in future iterations.
from stable_baselines3 import PPO
from rl.env import STLEnvironment
target_stl_path = "/project/stl_files/table.stl"
env = STLEnvironment(target_stl_path)
model = PPO("MlpPolicy", env, verbose=1)
#Training call for the model to learn, you can do it on GPU if you have access
model.learn(total_timesteps=100000)
model.save("/project/models/fine_tuned_llm.pt")
PPO fine-tunes the generator LLM by optimizing the policy that generates the .stl files. I use Stable Baselines3 which provides efficient implementations of PPO that can be adapted for LLM fine-tuning. A PPO agent that iteratively improves the CAD model by optimizing for performance metrics such as manufacturability, aesthetics, or specific design constraints. Once we have an initial model, the next step is to optimize the design using Reinforcement Learning (RL). Proximal Policy Optimization (PPO) is a popular RL algorithm known for its stability and performance in continuous action spaces, making it ideal for this task.
To apply RL to this problem, you also have to think of a unique optimization goal. This goal will help you access if your designs are getting any better or not, there is plenty research out there in this area, and I am happy to write another post about it in future. Some example to think about are things like minimizing material usage by reducing the volume of the model. We can also maximize structural integrity by ensuring specific stress distribution across the part. The RL agent will interact with FreeCAD, modifying the Python script generated by the LLM to improve the model according to these goals. The main difficualty here is integrating PPO into the Framework; The PPO agent interacts with the CAD model by modifying parameters such as dimensions, angles, or material thickness in the FreeCAD script. It does this iteratively, receiving feedback in the form of a reward, which indicates whether the new model is better according to the predefined objectives. Once the agent evaluates the generated model, receiving feedback (reward) based on how well it meets the objectives. We are then ready to update policy. PPO updates the agent’s policy to increase the probability of actions that result in higher rewards. This loop continues until the agent converges to an optimal design that satisfies the objectives.
-----------------------------------
| PPO Agent Initialization |
-----------------------------------
|
Modify CAD Parameters (Actions)
|
Generate CAD Model (State)
|
Receive Reward & Feedback
|
Update Policy (Optimization)
|
Loop until Convergence
-----------------------------------
Evaluation and Fine-Tuning
The model in my case certainly improved here is a case where I tried to generate an almond shape:
Without FineTuning

After FineTunning
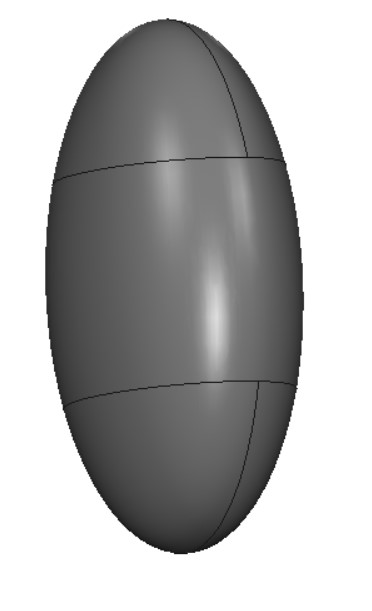
Once the PPO agent is trained, the optimized CAD models can be evaluated against predefined benchmarks. This could involve testing the model under simulated physical conditions to ensure it meets real-world requirements.
Further fine-tuning can be done by refining the reward function, adjusting the agent’s hyperparameters, or incorporating more complex constraints into the learning process.
Discussion
One of the things I would like to improve is the part constraint, being able to handle only certain amount of complexity is really defeating, despite all the fine tunning effort the generation process only improves so much. I have studied impact of using a larger LLM and how that impacts the quality of generation, and it certainly does have a huge impact, for example as of my most recent update with o1 series of GPTs the model can generate 12-14 parts output without any finetunning, but to rely on increased size of the model and to believe the scaling laws will always produce a step change in design is perhaps still a unknown territory and other ways are required to improve the overall 3D generation process.
References
[1] Phoebe Klett, Thomas Ahle (2024) “Extended Mind Transformers” https://arxiv.org/pdf/2406.02332 [2] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov (2017) “Proximal Policy Optimization Algorithms” https://arxiv.org/pdf/1707.06347 [3] FreeCAD blog post (2024) - https://blog.freecad.org/2024/09/20/tutorial-multiple-operations-from-a-single-sketch/