Introduction
There are two type of photon detection system one is conventional LiDAR probably most familiar to us because of its wide use in robotics, autonomous driving vehicles and many other ranging technology. The other type is less researched and not as widely used - single photon avalanche diaode(SPAD) sensor. SPAD sensor is used for similar usecase as conventional LiDAR like sensing and ranging but its much more sensitive than conventional LiDAR. It can detect when only a single photon is received back. This unique ability is due to the avalache diaode that allows it to notice object in far distances or object that might be very small in size. It is capable of measurement accuracy of less than 1milimeter and at pico sencond frequency. So for comparison what does that mean vs say an average camera, a camera captures 30 to 120 frame per seconds, a SPAD sensor captures 500 billion frames per second.
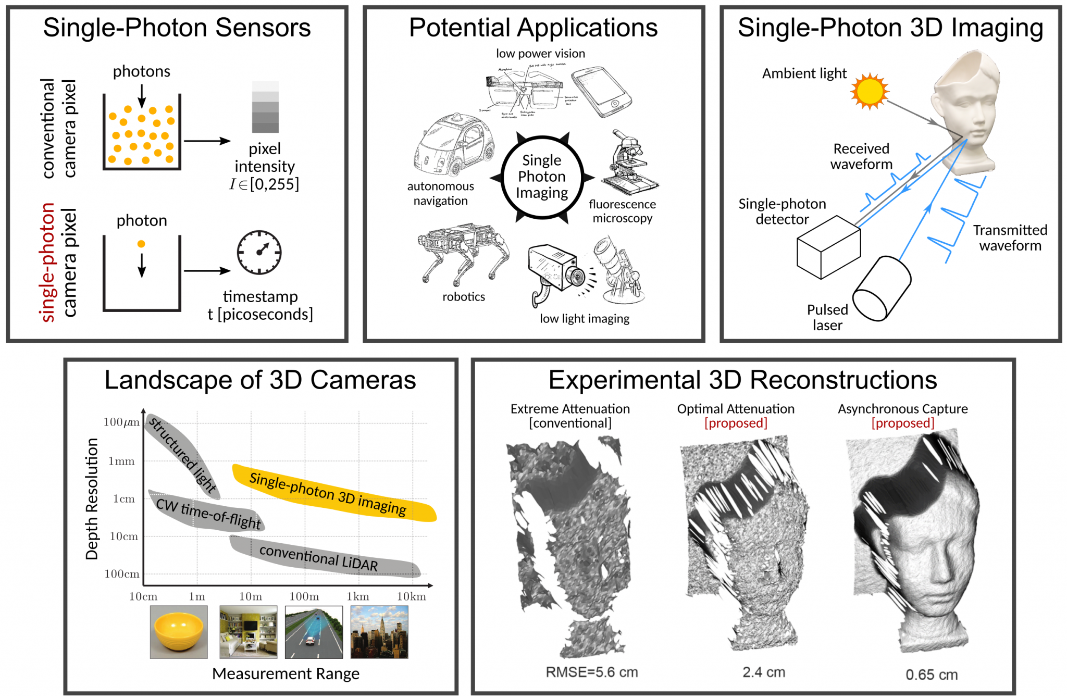 However, it is not free of challanges, for example SPAD sensor is prone to time jitter and dark noise. These noise are inherent in the sensor and there are other noise that happen due to atmospheric particles or other molecules in its ranging path.
In this article we will use some ideas from mature research in LiDAR technology in autonomous driving and see how those mature techniques can be implemented for identiication and classification of small microscopic objects that are suspended in space, or do not always exist on orthoganal axis like cars on road.
However, it is not free of challanges, for example SPAD sensor is prone to time jitter and dark noise. These noise are inherent in the sensor and there are other noise that happen due to atmospheric particles or other molecules in its ranging path.
In this article we will use some ideas from mature research in LiDAR technology in autonomous driving and see how those mature techniques can be implemented for identiication and classification of small microscopic objects that are suspended in space, or do not always exist on orthoganal axis like cars on road.
SPAD Sensor
 Single-Photon Avalanche Diode (SPAD) arrays are cutting-edge sensors that detect individual photons, making them highly sensitive with exceptional timing resolution down to picoseconds. These multi-pixel sensors can generate precise depth images, often with millimeter accuracy, making them critical for applications in autonomous systems where rapid guidance and situational awareness are essential.
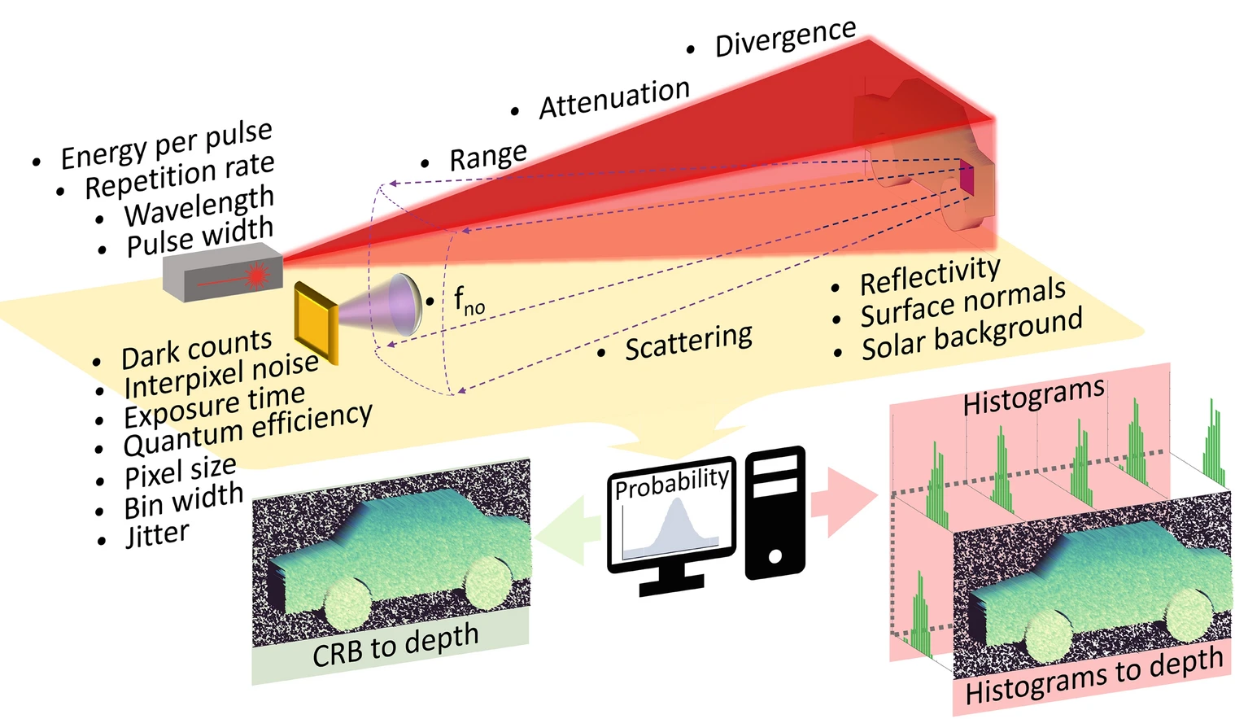
In my use case, I’m utilizing SPAD arrays for sensing, identification, detection, and classification of objects in long-range scenarios under low signal-to-noise ratio (SNR) conditions. The challenge lies in the fact that, while SPAD sensors can capture data with remarkable sensitivity, the noise levels, particularly in distant sensing, complicate accurate object identification and classification.
My goal is to harness SPAD’s photon-level sensitivity to detect weak signals at long distances, such as in satellite-based sensing applications. By establishing a robust numerical method that simulates real-world conditions, I can evaluate the best possible depth resolution and realistic imagery that SPAD arrays can achieve. This allows me to optimize detection and classification performance without relying on extensive and costly field tests. Ultimately, this system can be deployed in autonomous platforms for tasks like object tracking, and could also extend to specialized areas like underwater or non-line-of-sight imaging (e.g., imaging around corners).
Single-Photon Avalanche Diode (SPAD) arrays are cutting-edge sensors that detect individual photons, making them highly sensitive with exceptional timing resolution down to picoseconds. These multi-pixel sensors can generate precise depth images, often with millimeter accuracy, making them critical for applications in autonomous systems where rapid guidance and situational awareness are essential.
In my use case, I’m utilizing SPAD arrays for sensing, identification, detection, and classification of objects in long-range scenarios under low signal-to-noise ratio (SNR) conditions. The challenge lies in the fact that, while SPAD sensors can capture data with remarkable sensitivity, the noise levels, particularly in distant sensing, complicate accurate object identification and classification.
My goal is to harness SPAD’s photon-level sensitivity to detect weak signals at long distances, such as in satellite-based sensing applications. By establishing a robust numerical method that simulates real-world conditions, I can evaluate the best possible depth resolution and realistic imagery that SPAD arrays can achieve. This allows me to optimize detection and classification performance without relying on extensive and costly field tests. Ultimately, this system can be deployed in autonomous platforms for tasks like object tracking, and could also extend to specialized areas like underwater or non-line-of-sight imaging (e.g., imaging around corners).
Point Cloud Spatial Classification
The point cloud classification process in my approach directly use unordered points as input, while traditional methods had tried to represent the spatial relationship by using clustering or voxels, which made it quite difficult to achieve real-time performance due to increased computational processing required. In more recent years, deep learning-based methods have achieved SOTA performance in object classification using unstructured point cloud directly to learn spatial features, inspired by dense convolutional layers, which can acquire translation invariance, position invariance, and transform sparse point cloud into dense tensors to then learn feature representations. The top performing classifiers are generally PointNet++ or its variants; symmetric functions like max pooling are used in PointNet and PointNet++ architectures that summarize an outline of a region by extracting prominent features using multi-layer perceptron (MLP). These architectures are very effective when large sets of points are available to train, however, when only a small subset of points are available, max pooling exacerbates the issue of already low density of points by further reducing the feature space. PointNet++ and SOTA model variants also utilize a hierarchical learning process, which help in understanding spatial relationship at different scales. However, despite its ability to encode local features, it struggles with capturing the overall global spatial distribution of the point cloud, crucial deterministic information in understanding objects with very similar characteristics. There are ways to over come those but it cant be covered here as its not a topic of dicussion for this usecase.
Denoising point cloud
Noise cause the signal to noise ratio to drop significantly making it harder to recognize object in 3D point cloud data. This can also occurs if the scanning object with sensor is moving in relationship to the object its scanning. The impact of this motion is relative to the sensor’s sampling rate and integration time, which means if the motion is not as rapid then this will not cause additional noise in your data.
In order to denoise the data we need first begin with understanding where the object of interest is in relationship to us, this can be done by Point Density Aware Voxel Network (PDV) techniques.
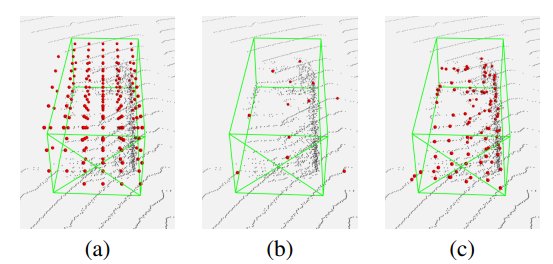 Voxel feature localization using (a) voxel centers, (b) farthest point sampling, and (c) voxel point centroids on a vehicle in
the Waymo Open Dataset.
PDV is a SOTA technique used in most advanced autonomous driving projects. It is used for 3D object detection architecture that accounts for point density variations, effectively localizes objects, and predicts precise length estimates. It utilizes voxel features from a 3D sparse convolution backbone through voxel point centroids. These spatially localized voxel features are then aggregated through a density-aware region of interest grid pooling method, employing kernel density estimation (KDE) and self-attention point density positional encodings.
Voxel feature localization using (a) voxel centers, (b) farthest point sampling, and (c) voxel point centroids on a vehicle in
the Waymo Open Dataset.
PDV is a SOTA technique used in most advanced autonomous driving projects. It is used for 3D object detection architecture that accounts for point density variations, effectively localizes objects, and predicts precise length estimates. It utilizes voxel features from a 3D sparse convolution backbone through voxel point centroids. These spatially localized voxel features are then aggregated through a density-aware region of interest grid pooling method, employing kernel density estimation (KDE) and self-attention point density positional encodings.
Unlike cars on road applying PDE to elements on wall or suspended in 3D space presents several challenges arise when implementing it for object detection. Although the method works well in one axis in detecting the precise dimention of a target object, it struggles in other 2 axis. As you will notice in figure above, the range varies significantly over the target’s track.
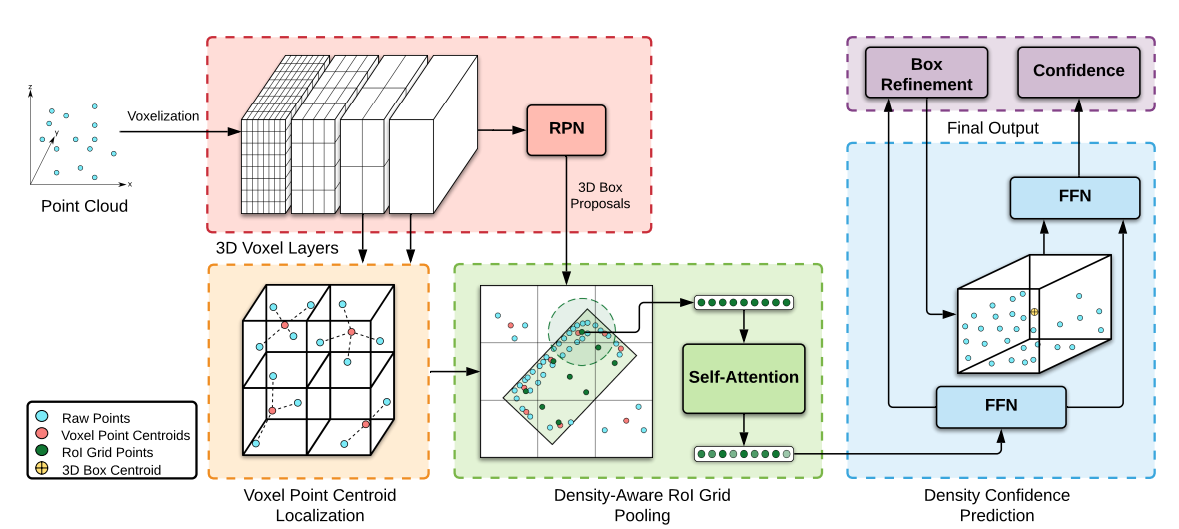 For very precise denoising we may have to run the algorithem in each axis to get a IoU region that will provide more accurate localization. Once we have localized our target object next step is to remove the noise outside the bounding box. In my expereince this takes care of 99% of any jitter or atmospheric noise and the final object then becomes quite easy to either train on or inference to classify.
For very precise denoising we may have to run the algorithem in each axis to get a IoU region that will provide more accurate localization. Once we have localized our target object next step is to remove the noise outside the bounding box. In my expereince this takes care of 99% of any jitter or atmospheric noise and the final object then becomes quite easy to either train on or inference to classify.