Real robot data is the most expensive ingredient in modern manipulation. Every demonstration is a human teleoperating an arm in real time - no parallelism, no fast-forward, and a fresh scene reset between every episode. Simulation is the opposite: parallel, cheap, and endlessly resettable, but it lies to you about contact, friction, and light.
So here is the question that drove this project:
Can VLA post-training run primarily on simulation data and still match a model trained exclusively on real demonstrations, for language-conditioned manipulation?
If the answer is yes, the data bottleneck largely dissolves: you generate the bulk of your demos in a simulator and spend your scarce real-world budget only where it actually moves the needle. This post is a deep dive into how we tried to answer that on a low-cost SO-ARM 101 - what we built, what we found, and the parts that did not work (which, honestly, were the most interesting).
This was my research project with Arizona State, collaborating with Aldrin Inbaraj (ASU Robotics PhD) and Venkata Rani (Google Research Intern). Everything below - datasets, fine-tuned checkpoints, the digital-twin stack, and the inference videos - is open-sourced; links are at the bottom.
The task in one clip: “pick a blue LEGO and place it in the blue cup,” run by a fine-tuned SmolVLA on an SO-ARM 101.
Where this question comes from
The anchor for our work is Maddukuri et al.’s “Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation” (arXiv:2503.24361). Their headline result is striking: for a Diffusion Policy taking RGB + proprioception, a sim-to-real co-training mix as extreme as ~99% simulation / 1% real gave the best real-world performance. Simulation, mixed in correctly, was almost a free lunch.
But there’s a catch that makes their recipe non-trivial to reuse. Diffusion Policy is a relatively small model with exactly two input modalities - pixels and joint states. A Vision-Language-Action (VLA) model is a different animal:
- it adds a language modality (the instruction conditions the policy),
- it is pretrained at large scale (SmolVLA, GR00T-N1, RT-2 all inherit web-scale or robot-scale priors before you ever touch them),
- and it is substantially larger, built on a pretrained backbone rather than trained from scratch.
Does a recipe derived for a small two-modality policy transfer to a large pretrained three-modality one? There’s no a-priori reason it should. A 99%-sim optimum for Diffusion Policy could easily become a different optimum - or no clean optimum at all - for a VLA. That gap is exactly what we set out to probe.
The task: deliberately boring on purpose
We chose language-conditioned LEGO color-sorting. Each episode is conditioned on an instruction of the form:
"pick a [color] LEGO and place it in the [color] cup" color ∈ {red, green, blue}
The cups are color-coded to match, giving a clean 3-batch design (red / green / blue) where color and target are bound together. The physical primitive - pick-and-place - is intentionally trivial.
That triviality is a feature, not a bug. We wanted the independent variable to be data composition, not task difficulty. If the task were a long-horizon, contact-rich assembly, any change in success rate could be attributed to a dozen confounds. By keeping the motion simple, the only thing that meaningfully varies across runs is the sim:real mixing ratio. Within the 6-month course window we executed the blue batch end-to-end (red and green are future work) with a paired corpus of 100 simulated + 440 real teleoperated episodes.
The hard part: making sim and real mixable
Here is the insight that ended up governing the whole project: you cannot blend sim and real data at training time unless they look almost the same to the model. If the simulated frames carry a large appearance shift relative to real frames, that shift swamps whatever effect the mixing ratio has - you’d be measuring “domain gap” instead of “ratio.” So before any ratio sweep is meaningful, the sim and real workspaces have to be visually matched.
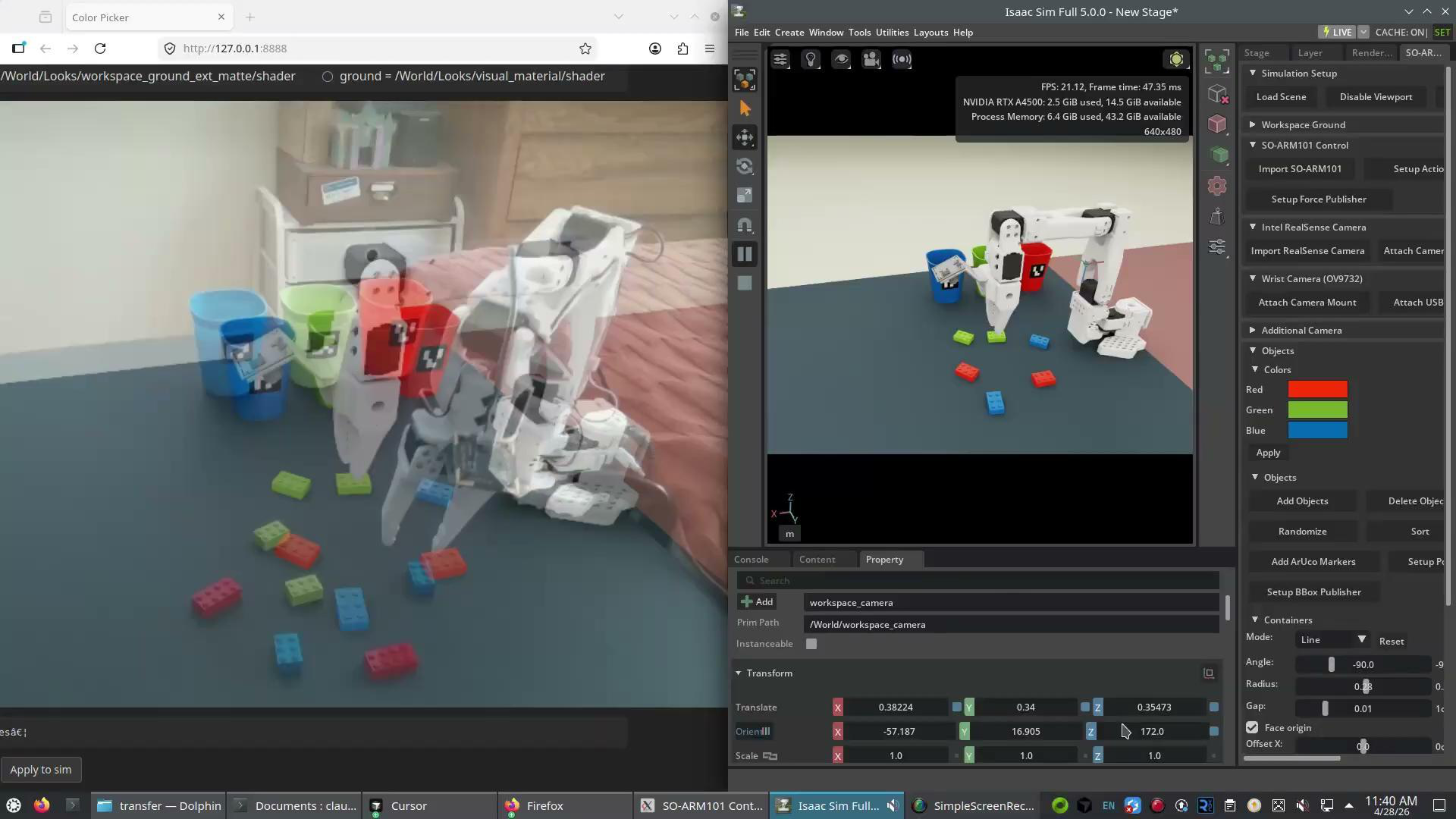
That meant building an SO-ARM 101 digital twin from scratch in NVIDIA Isaac Sim - matched cup colors, LEGO geometry, gripper viewpoints, and lighting - and wiring it into the same recording stack as the real robot.
 Real setup: leader-follower SO-ARM 101 with an overhead view (left) and the wrist camera (right) used during teleoperation.
Real setup: leader-follower SO-ARM 101 with an overhead view (left) and the wrist camera (right) used during teleoperation.
 The Isaac Sim digital twin, deliberately matched to the real scene - same cup colors, LEGO assets, and gripper viewpoint. This visual matching is the enabling condition that lets the two corpora be mixed without injecting an appearance-distribution shift.
The Isaac Sim digital twin, deliberately matched to the real scene - same cup colors, LEGO assets, and gripper viewpoint. This visual matching is the enabling condition that lets the two corpora be mixed without injecting an appearance-distribution shift.
Aldrin packaged this as a one-click Omniverse extension (soarm101-dt) that handles scene loading, RealSense + wrist-camera attachment, ArUco marker placement, randomized scene resets, and ROS2 publishers - so a simulated rollout is generated and recorded through exactly the same contract as a real one.
 The custom
The custom soarm101-dt extension: scene loading, randomization, camera setup, and ROS2 publishers behind one panel.
The real infrastructural win is subtle: sim and real share a single LeRobot recording contract. A simulated episode and a teleoperated episode land in datasets with identical schema - same observation.images.wrist, observation.images.top, joint state, gripper state, action, and the constant per-episode instruction string. They are interchangeable at the dataset-loader interface. That interchangeability is what makes a ratio sweep even possible.
 Generating simulation rollouts: object poses are sampled from the workspace distribution and a scripted IK controller executes the pick-and-place, recorded into the LeRobot format.
Generating simulation rollouts: object poses are sampled from the workspace distribution and a scripted IK controller executes the pick-and-place, recorded into the LeRobot format.
Curating the mixes (the part I owned)
My main contribution was the real-world corpus and the dataset curation - collecting 440 leader-follower teleop episodes, then building the five mixed datasets that the whole ablation depends on.
The mixing model is just a convex combination of the two domains:
D_λ = λ · D_sim + (1 − λ) · D_real λ ∈ {1.0, 0.75, 0.5, 0.25, 0.0}
where the subscript convention is the percentage of simulation: λ100 is pure sim, λ0 is pure real. The detail that makes this a clean experiment is the fixed budget: every mix contains exactly 100 episodes total, regardless of ratio. λ50 is 50 sim + 50 real; λ75 is 75 sim + 25 real, and so on.
Holding the episode count constant is the whole game. If you let higher-real mixes also have more episodes, you confound composition with quantity - and you’d never know whether “more real helped” because it was real or just because it was more. Fixing the total to 100 isolates composition as the sole variable.
Concretely, I pulled from a 100-episode sim corpus and the 440-episode real corpus, then used LeRobot’s dataset tools to slice and merge each ratio before pushing to the Hub:
# build_sim_real_mixes.py - one mix per ratio, each exactly 100 episodes
from lerobot.datasets.dataset_tools import merge_datasets, split_dataset
def build_one(sim_split, sim_full, real_full): # e.g. sim_split = 75
sim_count = sim_split # 75 sim episodes
real_count = TOTAL_EPISODES - sim_split # + 25 real = 100 total
sources = []
if sim_count:
sources.append(split_dataset(
sim_full, {"subset": list(range(sim_count))}, output_dir=sim_tmp)["subset"])
if real_count:
sources.append(split_dataset(
real_full, {"subset": list(range(real_count))}, output_dir=real_tmp)["subset"])
merged = merge_datasets(sources, output_repo_id=repo_id, output_dir=out_dir)
LeRobotDataset(repo_id, root=out_dir).push_to_hub() # → arjunsinghyadav2/...sim_and_real_{split}
All five splits are released as Hugging Face datasets. The point of releasing them is reproducibility: anyone can re-run the exact ratio sweep without reconstructing our corpus.
Training: SmolVLA, and FFT vs LoRA
We used SmolVLA (arXiv:2506.01844) as the base model - a compact, open VLA designed for affordable robots, which is exactly the regime we live in. Policy learning is framed as instruction-conditioned imitation learning. At each timestep the policy sees multi-view images, proprioception, and the instruction text, and predicts the next action, trained to match the expert:
L(θ) = E_(o,s,x,a)~D [ ℓ( π_θ(o≤t, s≤t, x), a ) ]
with an ℓ2 objective on the continuous joint actions across the six SO-ARM 101 DoF (shoulder pan/lift, elbow flex, wrist flex/roll, gripper).
We compared two fine-tuning paradigms:
- Full Fine-Tuning (FFT) across the five sim:real mixes - every weight is trainable, 100 episodes per run.
- LoRA on the entire 440-episode real corpus - a parameter-efficient counterpoint.
The FFT launcher pins the hyperparameters so the only thing that changes between runs is the dataset repo:
--policy.type=smolvla --policy.optimizer_lr=2e-5
--policy.freeze_vision_encoder=false --policy.train_expert_only=false
--policy.train_state_proj=true --policy.empty_cameras=1
--scheduler_warmup_steps=500 --scheduler_decay_steps=9000 --scheduler_decay_lr=1e-6
--steps=10000 --batch_size=32 --seed=42 # λ0 (100% real) extended to 50k steps
Compute was split across a local NVIDIA A6000 (48 GB) at the ASU lab and a rented H200 SXM (180 GB) on RunPod. A 10k-step FFT run took ~4.5 h on the H200, ~7 h on the A6000.
Loss curves already hint at the punchline
The FFT runs all behave themselves: a fast initial descent to a stable plateau within ~10k steps, essentially independent of the sim:real ratio. The model has no trouble fitting any of the mixes. LoRA is a different story - much noisier, much slower, and never quite settling even over 100k steps.
 FFT on 100% real (λ0): rapid descent, stable plateau - representative of all five FFT runs.
FFT on 100% real (λ0): rapid descent, stable plateau - representative of all five FFT runs.
 LoRA on real data: markedly noisier and still drifting at 100k steps. Fitting the data was never the easy part for LoRA - staying stable was.
LoRA on real data: markedly noisier and still drifting at 100k steps. Fitting the data was never the easy part for LoRA - staying stable was.
That “training loss looks fine” point matters: low training loss does not mean the policy transfers. The real signal is in evaluation.
Evaluating honestly: open-loop trajectory fidelity
How do you compare five policies fairly without 500 physical trials per model? We used open-loop trajectory fidelity against held-out teleop ground truth.
For each variant we replay one held-out teleop episode through the saved preprocessor, the policy’s predict_action_chunk, and the postprocessor, taking the first action of each predicted chunk as the command. That yields a T × 6 predicted joint trajectory we overlay on the human’s actual trajectory. The probe episode (#200 of the real set) is held out from every λ<1 variant.
The reason this is a clean probe: feeding identical observations to every model removes the closed-loop state divergence that would otherwise compound differently for each policy. Any spread between the curves therefore reflects only the mixing ratio λ - nothing else. It’s not a success-rate (that’s the honest limitation, and it’s deferred to future work), but as an ablation signal it’s cheap, deterministic, and fully reproducible.
![]() Open-loop tracking, per joint, against teleop ground truth (black). Pure sim (λ100) consistently fails to track - worst in shoulder and gripper. Injecting real data (λ75, λ50) pulls the curves back toward ground truth.
Open-loop tracking, per joint, against teleop ground truth (black). Pure sim (λ100) consistently fails to track - worst in shoulder and gripper. Injecting real data (λ75, λ50) pulls the curves back toward ground truth.
What we found
1. Pure simulation does not transfer - cleanly visible, not subtle. The λ100 (100% sim, 0% real) model consistently fails to track ground truth, most badly in the shoulder and gripper dimensions. In the real world it produces motion but misses the actual pick. So the strong form of our research question - “can it run purely on sim?” - gets a clear no for this VLA + task.
SmolVLA fine-tuned on 100% sim, then run on the real robot. It moves plausibly but doesn’t close the loop on the real LEGO - the sim-only policy didn’t acquire the right real-world grounding.
2. A modest dose of real data is what actually matters. Both λ75 (75% sim) and λ50 (50% sim) track the ground truth substantially better than pure sim. The first slug of real data is doing the heavy lifting - it re-anchors a sim-fit policy to real appearance and dynamics.
Inference from the 50% sim / 50% real mix.
3. But piling on more real data doesn’t keep helping. This is the counter-intuitive one. Going from a balanced mix toward heavily-real did not improve tracking further - and qualitatively, high real fractions made the policy noticeably jittery. Our reading: with a small, human-teleoperated corpus, extra real episodes add demonstrator variance faster than they add new coverage. Sim contributes clean, consistent geometry; real contributes grounding; but past a point, more noisy real just injects jitter. The sweet spot sat at a balanced-to-sim-heavy mix, not at either extreme.
That third finding is the real answer to our question, and it’s a genuine departure from the Diffusion-Policy result. Maddukuri et al. found ~99% sim optimal; for our VLA we found no single “golden ratio,” but a sweet-spot region where sim provides the bulk and a moderate amount of real does the grounding. The recipe does not port over unchanged - model class and modality matter.
The most instructive failure: LoRA’s gradient norm
The negative result I find most insightful is what happened to LoRA. Deployed on an unseen real rollout, the LoRA model couldn’t even approach the correct LEGO color. The training diagnostics explain why.
 LoRA gradient norm rises monotonically for ~40k steps, then plateaus with high volatility around 1.4-1.6 - no downward trend. The optimizer is pushing weights away from the pretraining distribution, not converging toward a solution.
LoRA gradient norm rises monotonically for ~40k steps, then plateaus with high volatility around 1.4-1.6 - no downward trend. The optimizer is pushing weights away from the pretraining distribution, not converging toward a solution.
A gradient norm that climbs and stays high - rather than decaying as the loss settles - is the signature of an optimizer that keeps trying to drag the weights out of the pretrained basin without ever finding a stable minimum. For a heavily-pretrained VLA, the likely culprit is LoRA target-module choice: if the low-rank adapters aren’t attached to the modules that actually need to change (the action head, the vision-language fusion layers), LoRA simply can’t express the required update - so it thrashes. FFT, which nudges all weights a little, stays inside the pretraining basin and converges.
The practical takeaway: parameter-efficient fine-tuning is not free for VLAs. Where you put the adapters is load-bearing, and getting it wrong is worse than full fine-tuning. We treat this as an actionable result - a directed sweep over LoRA target groups is top of the future-work list.
Toward autonomous data collection
Every real episode here was human-teleoperated, which is exactly the bottleneck we’re fighting. The Exploring-VLAs stack already includes the alternative: a hand-eye-calibrated YOLO-E open-vocabulary detector that estimates 6-DoF object poses and drives an IK controller to collect demonstrations without a human in the loop.
 YOLO-E overhead detector emitting 6-DoF poses for each LEGO, feeding the IK controller - the autonomous-collection path that replaces teleoperation in future corpus building.
YOLO-E overhead detector emitting 6-DoF poses for each LEGO, feeding the IK controller - the autonomous-collection path that replaces teleoperation in future corpus building.
This closes a nice loop: the same digital-twin + LeRobot contract that lets us mix sim and real can also generate real data autonomously, which is what it would take to scale a corpus to the size a real ratio-sweep convergence study demands.
Honest limitations
I want to be precise about what this study does and does not show:
- Single batch. Only the blue batch ran end-to-end; red and green are deferred, so the cross-color generalization the 3-batch design was built to test is not yet answered.
- Open-loop, not closed-loop. Our quantitative metric is per-joint trajectory fidelity, not multi-trial success rate. A closed-loop success-rate study across all five FFT ratios is the most important missing number.
- Real data is teleoperated. The 440-episode corpus carries human demonstrator variability - which is part of why high-real mixes got jittery, and a reason to move to autonomous collection.
What I’d tell my past self
A few things crystallized over six months:
- The optimal sim:real ratio is model-class-dependent. Don’t port a Diffusion-Policy recipe to a VLA and expect the same optimum. For our VLA, sim should carry the bulk and a moderate amount of real should do the grounding - more real is not strictly better.
- Visual matching is the unlock, not a nicety. The ratio question is only well-posed once sim and real are close enough that mixing them doesn’t itself create a domain gap.
- Hold the budget fixed. Varying composition while pinning total episodes is what turns a vague “sim helps” into a measurable curve.
- Watch the gradient norm, not just the loss. The loss curves looked fine for LoRA; the gradient norm told the real story.
- Most of the research was systems work. Building the twin and unifying the recording schema consumed the calendar - but it’s what made everything downstream measurable.
Reproduce it
Everything is open:
- Code / digital twin / recording stack: DIME-LAB/Exploring-VLAs
- Datasets (5 sim:real splits + the 440-ep real corpus): huggingface.co/arjunsinghyadav2
- Fine-tuned checkpoints (FFT λ-sweep + LoRA): huggingface.co/anirudhrani
- ArUco marker localizer: inbarajaldrin/aruco_camera_localizer
- All inference videos: YouTube playlist
This was a team effort for EEE 598 (Spring 2026) at Arizona State University. Aldrin Inbaraj built the Isaac Sim digital twin and the YOLO-E + IK perception package; I (Arjun Yadav) handled real-world teleop collection, dataset curation across the five splits, the FFT training infrastructure, and results analysis; Venkata Rani led the LoRA fine-tuning, the λ-sweep checkpoint training, and the gradient-norm failure investigation. Thanks to the open-source Isaac Sim, Isaac Lab, and LeRobot communities for making accessible robotics research possible.